
Power Query can extract data from an ever-increasing range of data sources and file types. Most sources are structured, making it easier to organise the contents into rows and columns, but Power Query can also work with content with a much less obvious structure – for example, PDF files.
Power Query can extract data from an ever-increasing range of data sources and file types. Most sources are structured, making it easier to organise the contents into rows and columns, but Power Query can also work with content with a much less obvious structure – for example, PDF files. There are circumstances in which extracting data from a single PDF might be useful but extracting and combining details from multiple PDFs is a more likely scenario.
For the past 15 years or so I have been sending my invoices electronically as PDF files. I store copy PDFs of each invoice in client folders. Consequently, I have a history of sales invoices for some clients going back as far as 2006. I decided to experiment with the capabilities of Power Query by seeing whether I could extract all the invoice PDFs from the client folder, extract the sales values and create a refreshable Excel Table as the basis for a PivotChart. Although the experiment was broadly successful, there are usually going to be easier and more reliable ways to connect to sales invoice information. However, the ability to extract data from PDF files, and the techniques involved, will also have more practical uses.
The starting point is to use the Data Ribbon tab, Get & Transform Data group, Get Data dropdown. From this dropdown, the From File, From Folder command allows you to browse through your file system to find and select the appropriate folder:
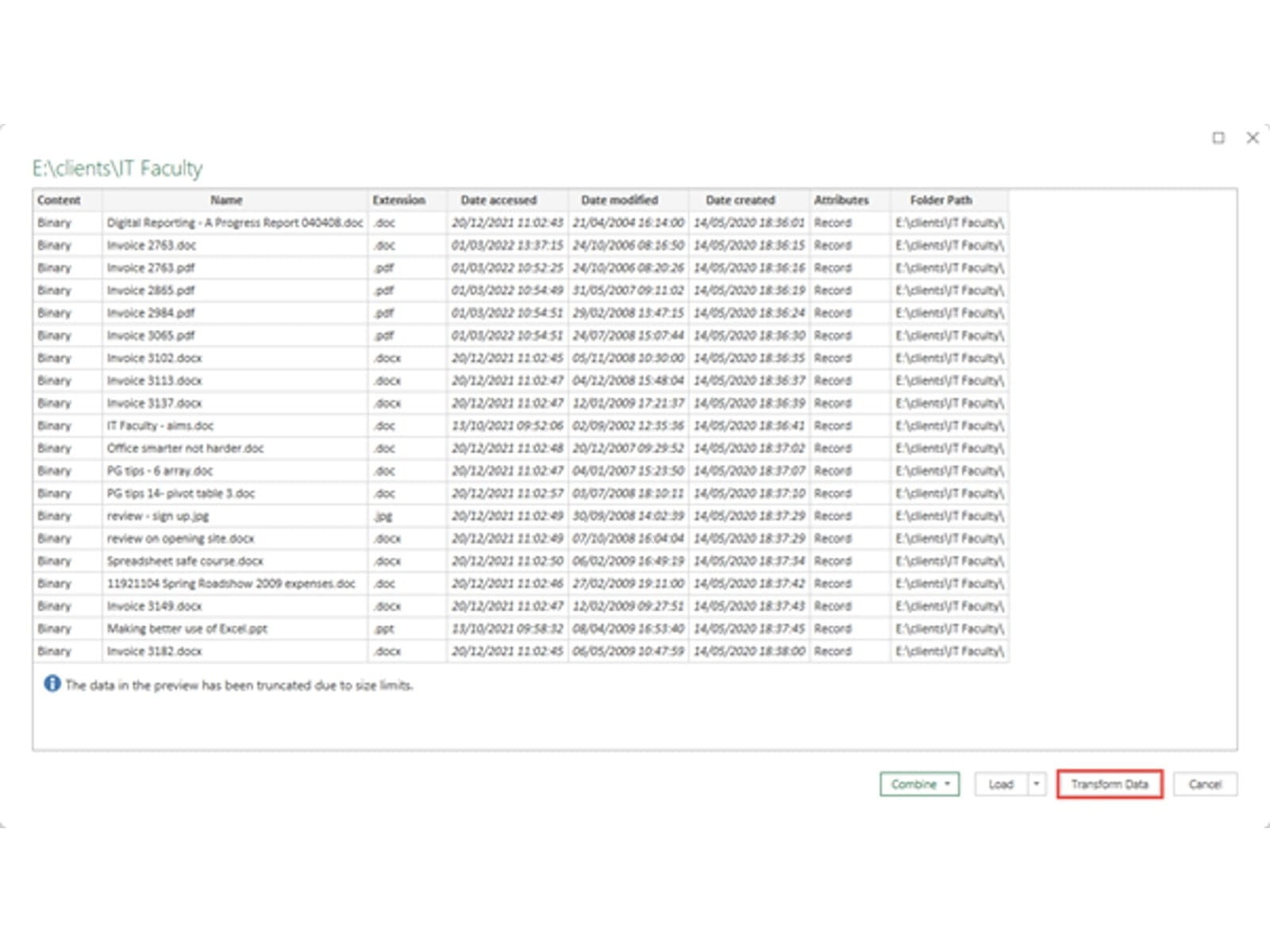
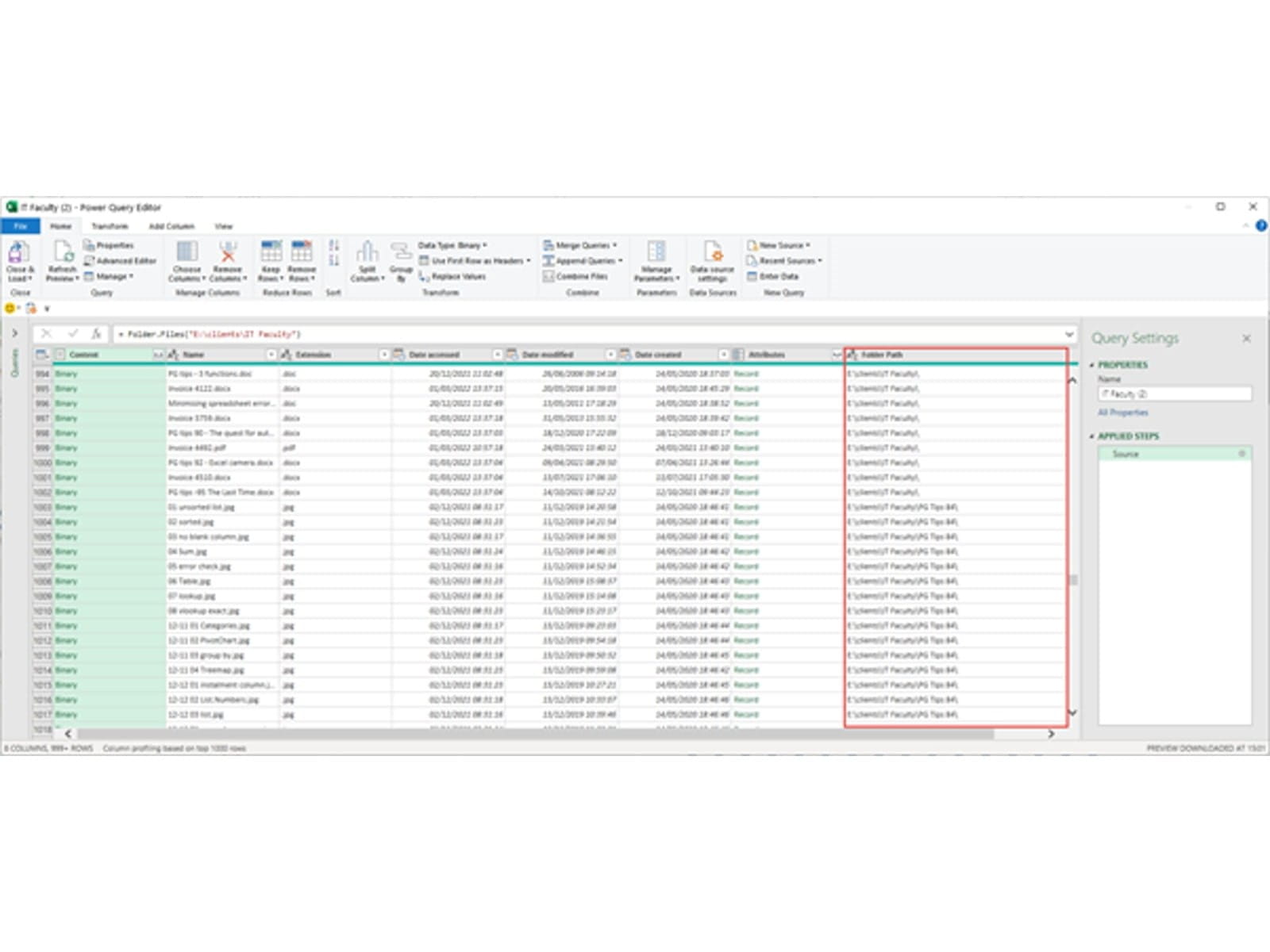
Having located the folder, we can use click the Transform Data button to start working with all the files in that folder. Note that Power Query also retrieves files in subfolders:
Our first step is to narrow down the files we want to consider to those with the PDF extension and, in our case, to filter the PDFs themselves to those that begin with the word Invoice (being careful to get the capitalisation right as the filter is case-sensitive):
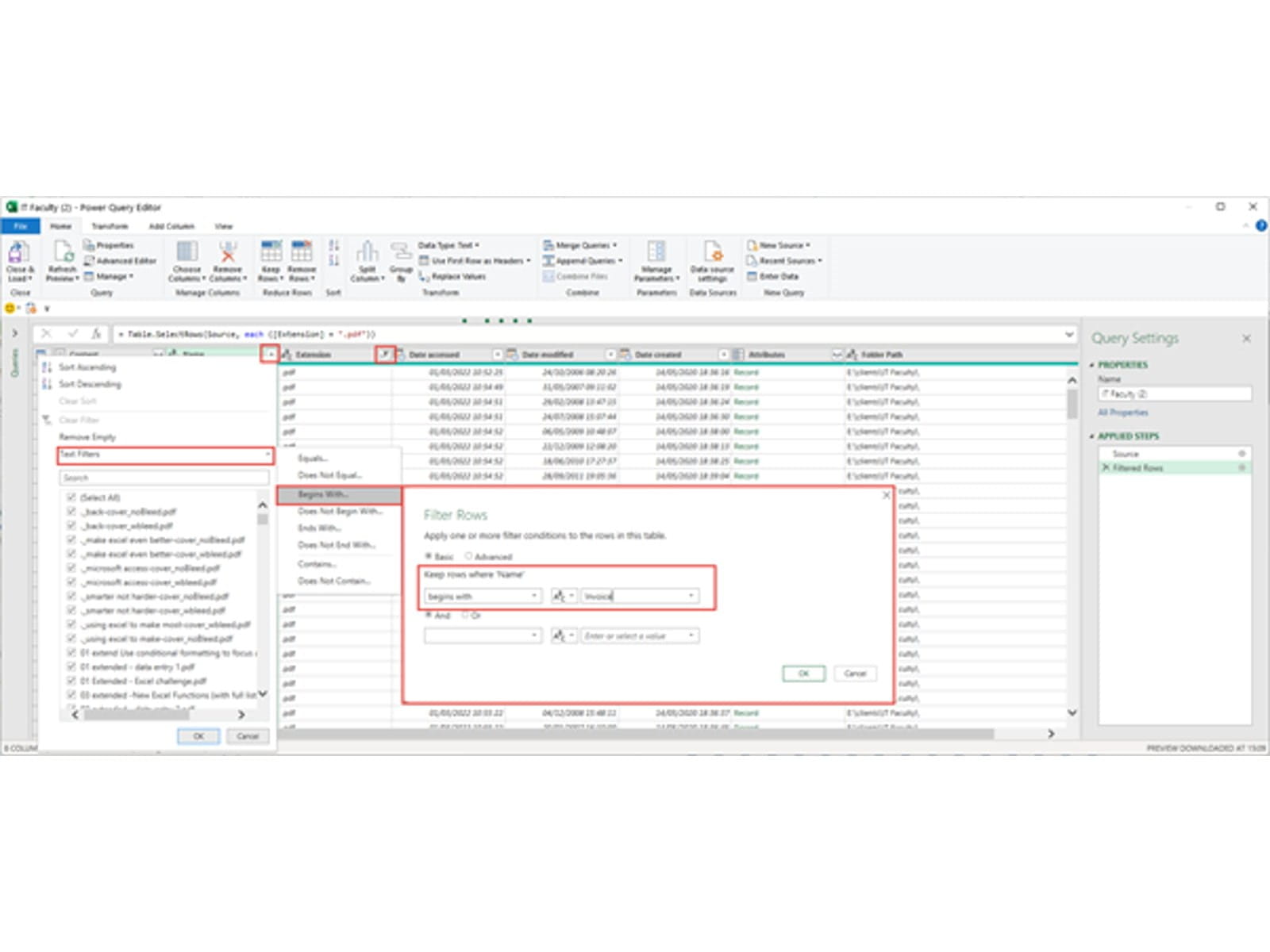
It might seem obvious, but there is a significant point here in relation to the performance of queries. Wherever possible, reduce the amount of data that you are working with as early as possible. This is a particularly stark example, because if we didn't filter our files before we expanded them to get at the data they contain, we would end up performing complex operations on far more files than we actually need to.
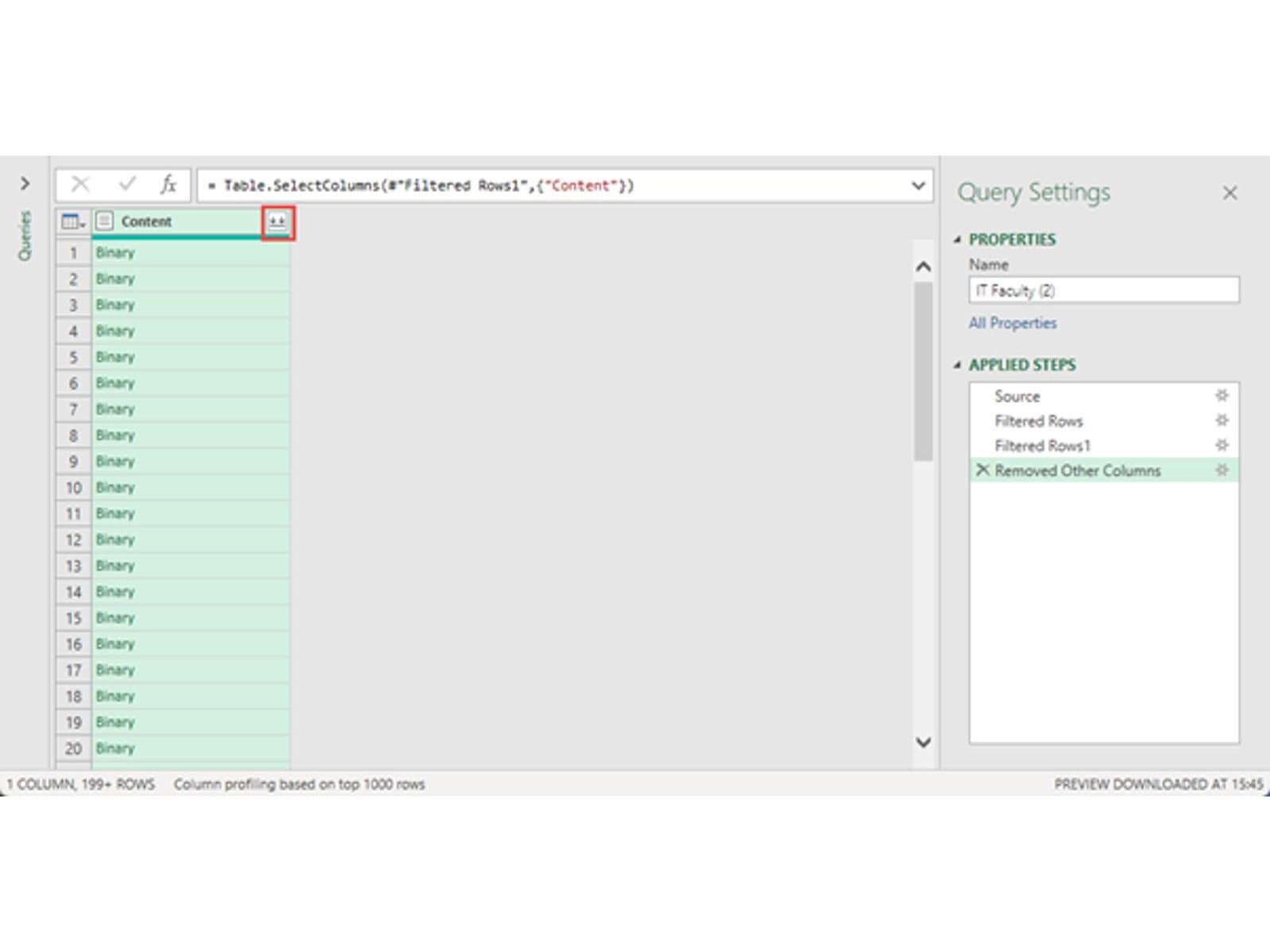
Having used our Name and Extension columns to filter our list of files, the only column we need to use is the Content column so we can right-click in the Content column header and choose to Remove Other Columns. We can then click on the Combine Files icon at the right of the Content column header:
This launches the Combine process and will use the first file as a sample to allow you to navigate to the part of the file that you want to use. Where the sample file includes recognisable tables, these will be displayed so that, if all the files are consistent, you can just work with that part of each file. Alternatively, you can import entire pages of the PDF. I can't really go any further without making a terrible admission: for strange, historical reasons that we don't need to go into, I produce my invoices using Microsoft Word. I do use a template which does greatly improve the consistency of the structure of the PDFs and consequently gives me a chance of extracting the data, but over the 15 or so years, a few changes have crept it. Accordingly, I needed to import the whole page from each PDF rather than being able to select a single table element:
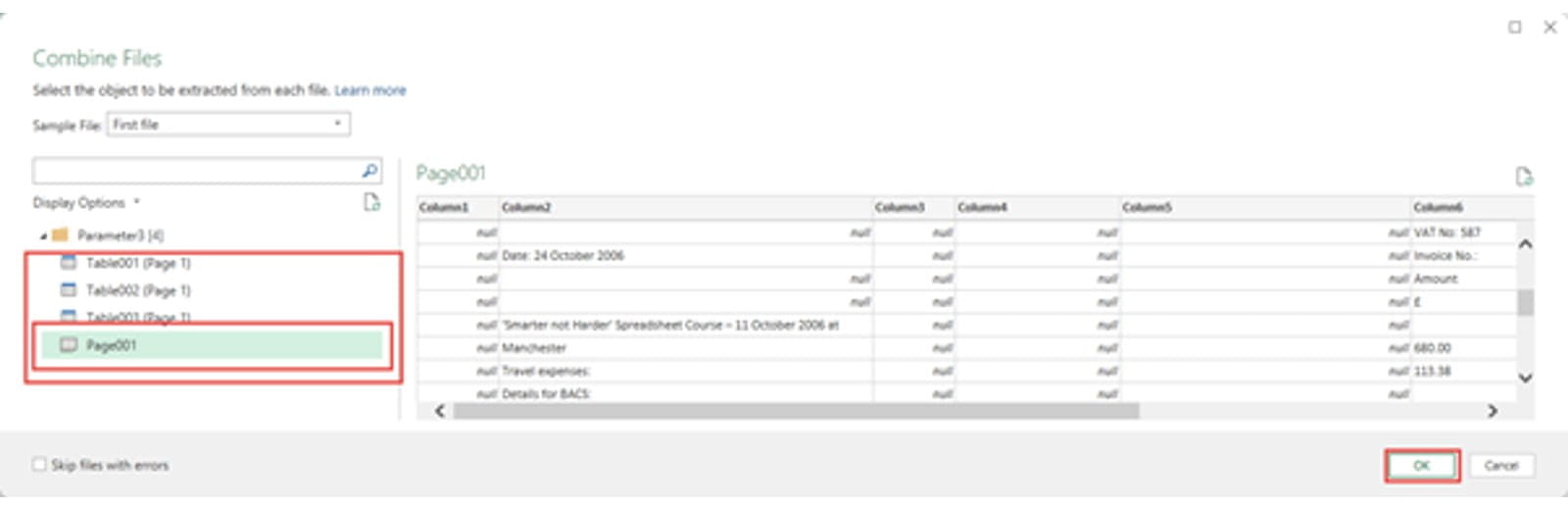
When we click on the OK button, Power Query then uses our selection to create a function that will extract the information from each of our other files in turn. We covered this process in detail in a previous post: Analysing data from multiple workbooks - Part 2: setting an example . In the Queries pane on the left we can see the set of 'Helper Queries' that Power Query has created for us to extract the data from each of our 280 or so PDF files:
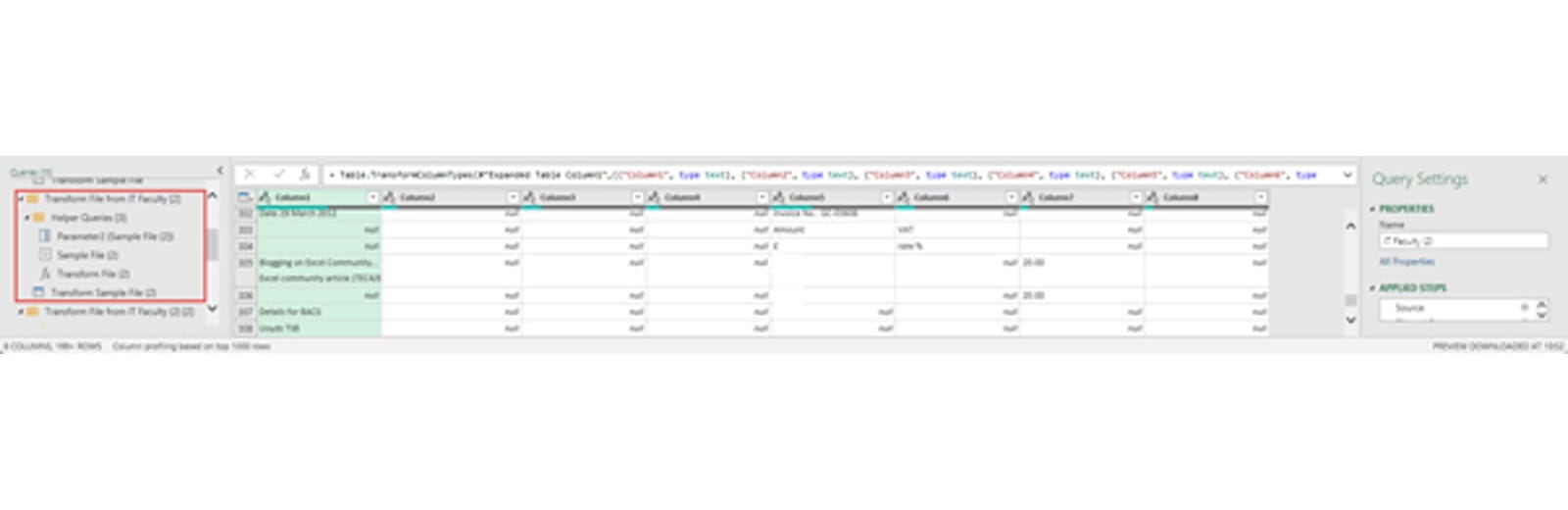
A lot of work remains to transform our unstructured PDFs into a table of invoice values. The main issue is that the actual invoice value varies from being in column 3 to column 7 which involves ensuring that all the values in those 5 columns are either a valid number or replaced with a 0, then adding a custom column that combines all the values into a single column:
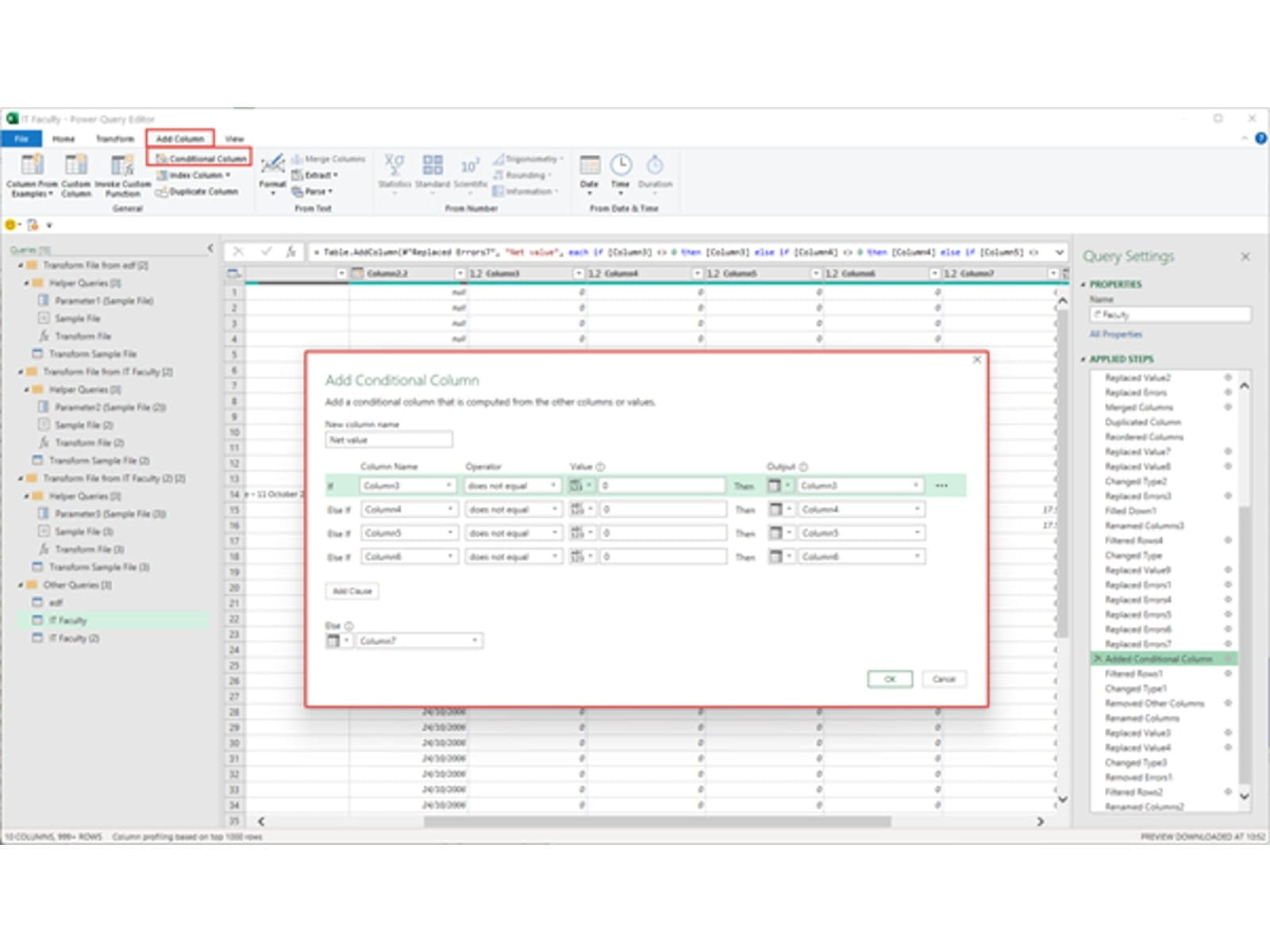
After that, most of the remaining steps involve filtering out unwanted rows and removing unneeded columns. The resulting query is then loaded to an Excel Table that could be used as the basis for our PivotTable and PivotChart:
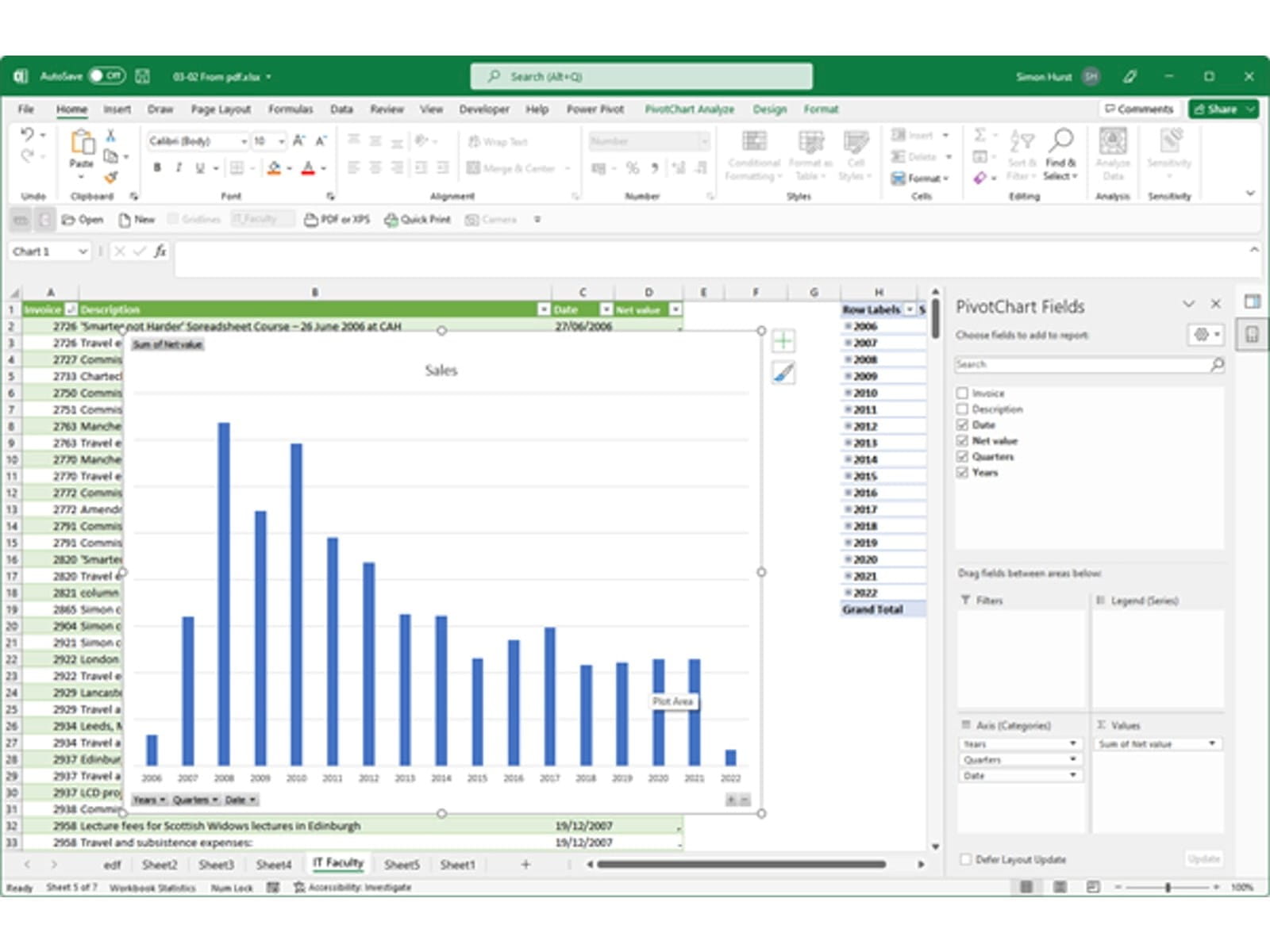
Although the process of extracting and transforming the data from over 280 PDFs was reasonably successful, the results do need to be reviewed very carefully. One of the PDFs in the folder looked similar to all the others, but ended up with the bank account number where the net invoice amount should have been, temporarily boosting the 2015 sales figure by several £million…
Related links
Excel Tip of the Week #389 - Power Query Dropping Rows and Columns
Analysing data from multiple workbooks - Part 1: automation, automation, automation
Analysing data from multiple workbooks - Part 2: setting an example
Archive and Knowledge Base
This archive of Excel Community content from the ION platform will allow you to read the content of the articles but the functionality on the pages is limited. The ION search box, tags and navigation buttons on the archived pages will not work. Pages will load more slowly than a live website. You may be able to follow links to other articles but if this does not work, please return to the archive search. You can also search our Knowledge Base for access to all articles, new and archived, organised by topic.
