
Three new text functions have been introduced in Excel to help extract values from text containing some sort of delimiter. We take a detailed look at some of the arguments available as part of these new functions to help you to get the most from them and also highlight some significant changes between the preview and release versions of the functions.
New text functions
In a recent post, David Benaim looked at three new text functions that are now being made generally available to Excel for Office 365 users. Although David provided an excellent summary of the new functions, it’s worth looking at the function arguments a little more closely, not least because those arguments have changed since the functions were originally released as preview features.
TEXTSPLIT()
This is particularly true for TEXTSPLIT() where the change in arguments could cause issues with any formula created with the preview version. In fact, this is the second time in recent years that an argument change has affected how an existing formula might work. As Liam Bastick explained about 3 years ago, the order of arguments within the XLOOKUP() function was changed between preview and general release:
With TEXTSPLIT(), the preview version included five arguments:
Required arguments:
- The text to be split (preferably a reference to a cell containing that text).
- The character, characters, or list of separate characters, that will be used as delimiters to split the text into separate columns.
Optional arguments:
- The character, characters, or list of separate characters, that will be used as delimiters to split the text into separate rows.
- Whether consecutive delimiters, with no value between, should create an additional cell or not.
- The value to ‘pad’ empty cells with when rows contain different numbers of values.
The released version squeezes an additional argument between the last two optional arguments described above. This additional argument allows you to specify whether, when one or more text characters are used for the delimiter, the match with the original text should be case sensitive. This also has, at the time of writing, the effect of converting all the return values to lower case, which might not have been intended or even desirable.
If just the first three arguments are used, TEXTSPLIT() will default to creating additional empty cells where the value in the text is empty; to case sensitive matching with delimiters and to returning the #N/A error for empty cells:
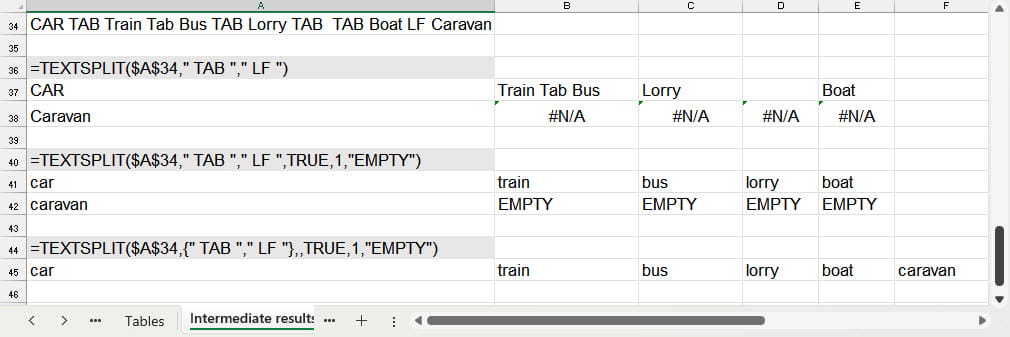
Here, we can see that our first formula doesn’t match TAB with Tab, leaves a cell between Lorry and Boat and fills empty cells with #N/A.
Our second formula sets the fourth argument to TRUE to ignore the consecutive delimiters between Lorry and Boat; sets the fifth argument to 1 to stop our match being case sensitive and thereby matches TAB with Tab and finally our sixth argument pads the empty cells on our second row with the text EMPTY.
The other important point David made in his post was that it is possible to enter a list of separate values as the ‘split by column’ or ‘split by row’ argument to cause any one of the items in the list to work as a delimiter. Our third example removes the ‘by row’ argument and instead puts both our delimiters in the ‘by column’ argument. The curly brackets or braces are used to show that we want to use a list of values:
{" TAB "," LF "}
As you can see in the example, either of the TAB and the LF delimiters now act as row delimiters.
TEXTBEFORE() and TEXTAFTER()
There is not a great deal to add to David’s explanation of these two functions beyond noting that, like TEXTSPLIT() they have benefited from a change in the available arguments. In the case of TEXTBEFORE() and TEXTAFTER(), both have two additional arguments, and this time they have been added after the original arguments, thereby reducing the likelihood of issues with formulae created with the preview versions.
We’ll start with a quick recap of the first four arguments which are similar for both functions:
Required arguments:
- The text to be split (preferably a reference to a cell containing that text).
- The character, characters, or list of separate characters, that will be used as delimiters to split the text into separate columns.
Optional arguments:
- Which instance of the delimiter to use to split the text. Note that a positive number will count delimiters from the beginning of the text and a negative delimiter will count them from the end. The default is to find instance 1, counting from the beginning.
- Whether, when one or more text characters are used for the delimiter, the match with the original text should be case sensitive or not. Unlike TEXTSPLIT() this does not convert the output text to lower case. The default is to perform a case sensitive match.
Our two new arguments control:
- Whether the end of the text should be treated as a, notional, delimiter.
- The value to return if the designated delimiter is not found. This defaults to displaying the #N/A error.
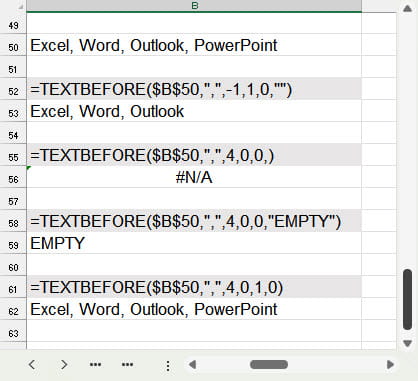
We have used TEXTBEFORE() for these examples. TEXTAFTER() works in the same but returns the text after the delimiter rather than the text before the delimiter.
The first formula shows the use of the instance number entered as a negative to count the instances of delimiter from the end of the text. We have also entered the fourth argument as 1 to perform a non case sensitive match which, given we haven’t used any letters as delimiters, won’t make a difference but does show that, unlike the same argument in TEXTSPLIT(), this doesn’t affect the case of the returned text.
The second formula looks for the fourth instance of the delimiter but, as we have only entered three delimiters, returns the #N/A error.
The third formula uses the fifth argument to replace the #N/A error with the word EMPTY.
The fourth formula sets the end of the text to be treated as a notional delimiter, so the fourth instance of our delimiter matches the end of the text, meaning that we return all of the text rather than an empty cell.
Archive and Knowledge Base
This archive of Excel Community content from the ION platform will allow you to read the content of the articles but the functionality on the pages is limited. The ION search box, tags and navigation buttons on the archived pages will not work. Pages will load more slowly than a live website. You may be able to follow links to other articles but if this does not work, please return to the archive search. You can also search our Knowledge Base for access to all articles, new and archived, organised by topic.
