When thinking about the content for this article, it struck me that whilst my previous article gave what I think is a good example of using the requests library in Python, this may not necessarily be the best approach in your environment as it is synchronous in nature (more on this below).
Before using the Companies House Documents API, it is first necessary to get to grips with the difference between synchronous and asynchronous API calls. If you understand what I mean by this, then feel free to move on to the implementation of an asynchronous client for obtaining company profiles from Companies House – the second part of this article.
For this article, I am going to make an assumption that you have a basic understanding of Python, and I will also utilise code and approaches as discussed in my previous article.
All code can be found on the async-documents branch of the repo on GitHub.
Synchronous vs asynchronous
What do I mean by these terms?
Synchronous – each operation depends on the completion of the one before it before moving on, i.e. each operation blocks the next.
Asynchronous – allows for operations to “pause” whilst waiting on a result giving the impression of running tasks concurrently with each other, i.e. it is non-blocking in nature.
Why is this relevant to my previous article? Well, that is because the requests package is blocking, i.e. it is synchronous.
Now consider a use case for the Companies House API where maybe we want to scrape a lot of data from companies we engage with, maybe to see if there’s been any updates to the PSC register for example. If we have hundreds of these then in the synchronous approach each request will need to finish prior to the next one starting despite each request being entirely different and not dependent on the outcome of one another.
So, in the above scenario, using an asynchronous approach will allow multiple requests to run without waiting for the result of one request to execute.
I always found the switch from synchronous to asynchronous uncomfortable to begin with, as synchronous just feels much more logical, and I find the explanation here brilliant for those that are curious about the concept and how it generally works.
An example
I always feel it’s better to run an example to explain how this works, and to do this, we use Python’s built in asyncio package, the foundation from which we can, and other packages do, implement asynchronous capabilities.
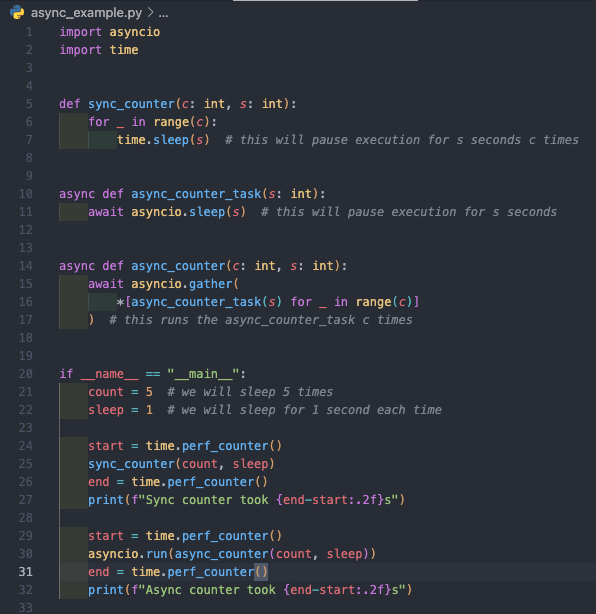
The code above is hopefully quite simple to understand and does the following:
- sync_counter is a function that will sleep for s seconds c times in a synchronous fashion, i.e. waiting for the previous sleep operation to complete.
- async_counter_task creates a coroutine (see below) for sleeping s seconds using the asyncio.sleep method.
- async_counter aggregates this coroutine c times using the gather method, to allow each coroutine to be scheduled and run on the event loop (see below).
A coroutine can be thought of as a task that can be suspended and resumed, in essence freeing up execution for other tasks whilst idle or waiting for a result, i.e. in an asynchronous fashion. Simply calling a coroutine will not actually execute it, but instead create a coroutine object.
To execute these coroutines, we need an event loop, which essentially handles the execution of all coroutines and managing when they suspend and resume. This is where the asyncio.run() method comes in, as this starts an event loop upon which to execute coroutines that are passed to it. Think of the event loop as the programmatic version of a conductor of a grand orchestra, controlling how instruments harmonise with each other.
Based on the definitions I gave earlier, we should at least have an expectation that the sync_counter function should run in roughly 5 seconds, as we are waiting 1 second 5 times. The output shows how using asyncio can generate performance gains for certain tasks (see below):
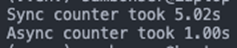
As we can see the asynchronous version ran all 5 tasks in 1 second as they were run without blocking each other whilst the function slept.
Asynchronous, multithreading and multiprocessing often come up when talking about concurrency, and I’m not going to delve into any more detail on this topic here as there is plenty of material on this – an example overview can be seen here for those interested.
In general, we would choose asynchronous programming with a large number of I/O bound tasks, i.e. when the time to execute is primarily dependent on waiting for inputs or outputs, for example waiting for a response from a HTTP request sent to a web server via an API – hopefully you can see why this is relevant!
Creating our asynchronous client
Whilst there are a couple of different Python packages we can leverage, the one I am going to use is aiohttp which is an async-only package.
To begin with I’m going to create a minimal example of an asynchronous HTTP client and then compare the performance to the synchronous client from my original article, whilst also borrowing some of the class attributes as well.
My minimal example will involve obtaining the company profile, so first I add the get_company_profile method to our CompaniesHouseAPI class that runs synchronously using the requests package:

Hopefully the above is self-explanatory given the information provided in my previous article, and is based off the API specification for this endpoint.
Using the same sort of structure in our asyncio example above, we create our coroutines to send these requests using the aiohttp.ClientSession object which is described as best practice here.
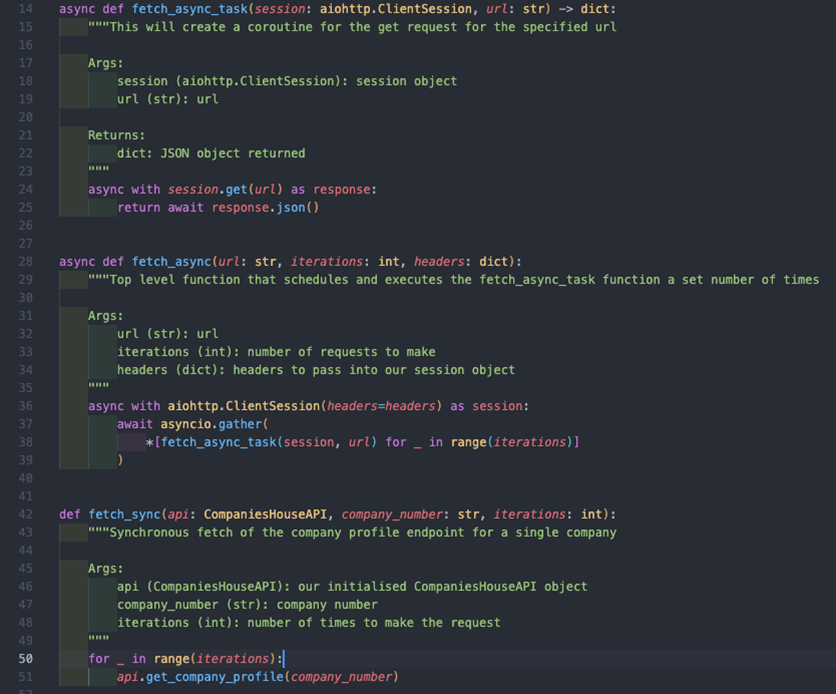
The above operates as follows:
- fetch_async_task creates a coroutine to be executed that makes a GET request to the specified URL and returns the JSON response.
- fetch_async aggregates this coroutine a fixed number of times equal to the iterations and also passes in any headers to the ClientSession object, which we require in order to authenticate to Companies House – again we use the asyncio.gather method for doing this.
- fetch_sync uses our CompaniesHouseAPI class to make a get call to the company profile endpoint a fixed number of times equal to iterations.
To see the performance of both the synchronous and asynchronous approaches, we want to establish our parameters, run a benchmark for a single request, and then compare to the performance of both scenarios. I have done this like so:
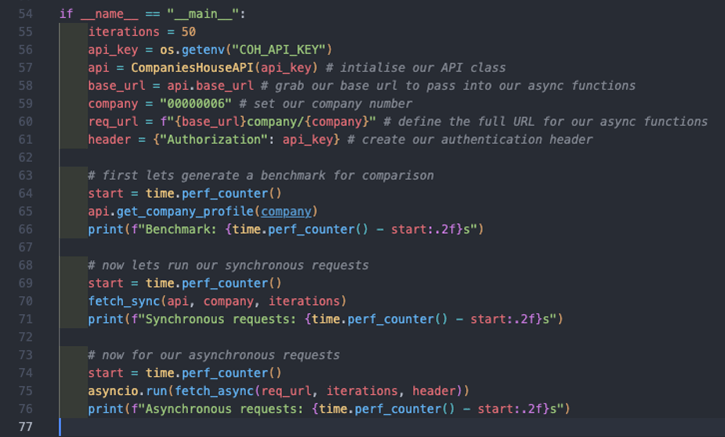
I’ve included comments where relevant to describe the steps taken. I ran this 3 times, as given the nature of HTTP requests, the response times are likely to vary, and these are the results:
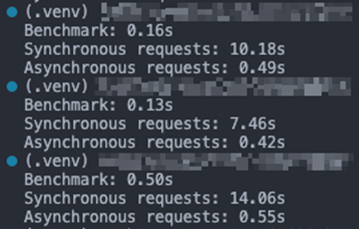
Despite the third benchmark being wildly different, the asynchronous approach shows a clear sign of performance improvement of over 95%, with each request not being blocked by one another.
In part 2, Sam will explore how to apply this to using the Companies House Documents API.
About the author
Sam is a Chartered Accountant and Auditor with a keen interest in technology. He has previously managed an audit portfolio whilst leading an Innovations team building internal analytical tools for audit and providing automation and analytics to clients.
He now works at Circit, as a Product Manager for their Verified Transactions, Verified Insights and Verified Analytics modules.
Feel free to reach out to Sam at sam.bonser@circit.io.