Machine learning – Explained simply
Machine Learning is, as its name defines it, a machine who learns. The first reference of Machine Learning dates back to 1959 and attributed to artificial intelligence and computer gaming pioneer; Arthur Lee Samuel. 63 years later and “self-teaching computers” (another term for Machine Learning) are revolutionising every industry, from healthcare to finance, marketing, and agriculture.
Imagine yourself at the supermarket, shopping for your weekly meals. You pass through the fruit and veg section. You are looking to buy some fruits today, so you have to sort through the section to find fruits instead of vegetables.
Your assessment of identifying fruits out of a mix of fruit and vegetables is based on your lifelong experience of distinguishing and understanding the difference between fruits and vegetables. As a child you most likely found it harder to distinguish between the two, with your parents explaining that “these are fruits not vegetables”, thus improving your experience of distinguishing between the two categories.
This is exactly how Machine Learning works. You are the computer; your parents providing the human input and the fruit and veg is the dataset.
Let us visualise this a bit.
I save the following images on my computer and feed them to the algorithm.

Then (as my parents did to my younger self), I label these as vegetables or fruit, so the computer can identify what I mean by each.

Assuming that my Machine Learning model does now have a better idea of what is meant by fruit and vegetable by providing it with the above set of images (let’s call it “the training set”), I want to test how accurate it is by providing it with a new set that it has not seen before (“the testing set”).

I do not label my shopping as fruits or vegetables, I let the computer do that to test how much it learned from before. Let us say the computer has concluded the following.

As my ML (machine learning) model labelled 4 out of 6 fruits and vegetables correctly, I can say that it has a prediction accuracy of 67% (4/6); which is quite low. So, what do I do? I feed it with more labelled images to improve its prediction accuracy, which will keep increasing with the more data/experience it has.
This is known as Supervised Learning. We have supervised our model (by labelling our fruit and vegetable dataset) to come as close as possible to a human expert in predicting an outcome.
| Real Business Case – Insurance industry |
| Insurers have decades of labelled data relating to claims and damage and many are using machine learning to improve operational efficiency, from claims registration to claims settlement. These insights save millions of pounds in claim costs through proactive management, fast settlement, targeted investigations, and better case management. |
Alternative Learning Models
There are two further types of Machine Learning that we will cover: unsupervised learning, and reinforcement learning. Unsupervised learning is, quite simply, providing a system with training data but without labelling it. So, with the fruits and vegetables example above, we provide the same images, but we do not tell the computer which are fruit, and which are vegetables.The algorithm is designed to find its own groupings and patterns in the data, sometimes uncovering structures that human observers miss. Some examples of groupings (or clusters) that the model identifies are shown below:


In Clustering One, the model has grouped the fruits and vegetables based on their colour, whereas in Clustering Two based on their shape.
Providing my unsupervised model, then, with a picture of a melon , it will decide how to treat it and will most probably add it with the yellow-coloured fruit and veg in the first type of clustering and with the round-shaped fruit and veg in the second group of clusters.
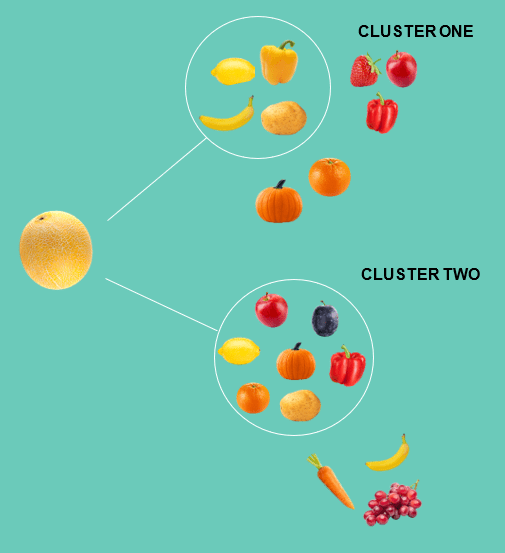
| Real Business Case – Entertainment industry |
| Netflix uses unsupervised learning algorithms to discover groups of customers to improve its recommendation of movies and series. While we can ‘rate’ shows on Netflix (a form of labelling), most users do not, so the algorithm only knows what we have watched. From this, it tries to determine what we might like to watch. |
Unlike supervised learning models, which is training the system to recognise known outcomes, unsupervised learning models are used to discover insights in data.
This was an example of clustering, one of the three types of unsupervised learning.
Association rule mining is another type of unsupervised learning – assessing the likelihood of an action based on past behaviours. Is it a coincidence that the supermarket next to the gym is always selling out of almond milk? An unsupervised learning model might try and explore that and other relationships between the customers of the two places, to help ensure the stock controllers for the supermarket buy the right products (and could further help by determining the best location to put them in the store to maximise footfall and sales).
Association rule mining will therefore look for frequency and co-occurrence among any set of items and then create associations that are likely to occur between several types of products.

| Real Business Case – Retail industry |
| Amazon and Ocado use association rule mining to provide recommendations to customers for additional products based on the current set of products in their shopping cart and similar customers. |
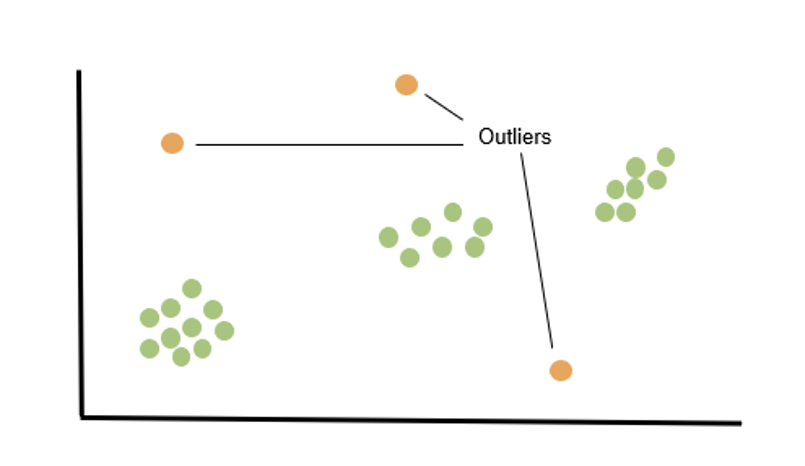
The last type of unsupervised learning is anomaly detection, which really defines itself. The algorithm will look at each new incoming datapoint/image/transaction and will make the judgement whether it follows prior patterns or if it should be flagged as anomalous/unfitting. This has particular value in fraud detection and is a key tool available to many banks as they run checks on card transactions in real-time.
Reinforcement learning
Reinforcement learning, the last out of the three types of Machine Learning, is still an underdeveloped machine learning type, with the potential, however, to be more impactful than both supervised and unsupervised learning.Let us observe a real-world example – puppy training. The words “sit”, “hand” or “fetch” are not in a new puppy’s dictionary, so they somehow have to be learned, using a reward. Every time I used the word “sit” and my puppy sat, she was given a salty treat (positive reinforcement). At the same time, she was also learning what not to do when faced with negative experiences - being called a ‘bad dog’ (negative reinforcement). By interacting with the environment, my puppy (the agent) will either sit or walk (change state) and expect a reward in return (me giving her treats or not).
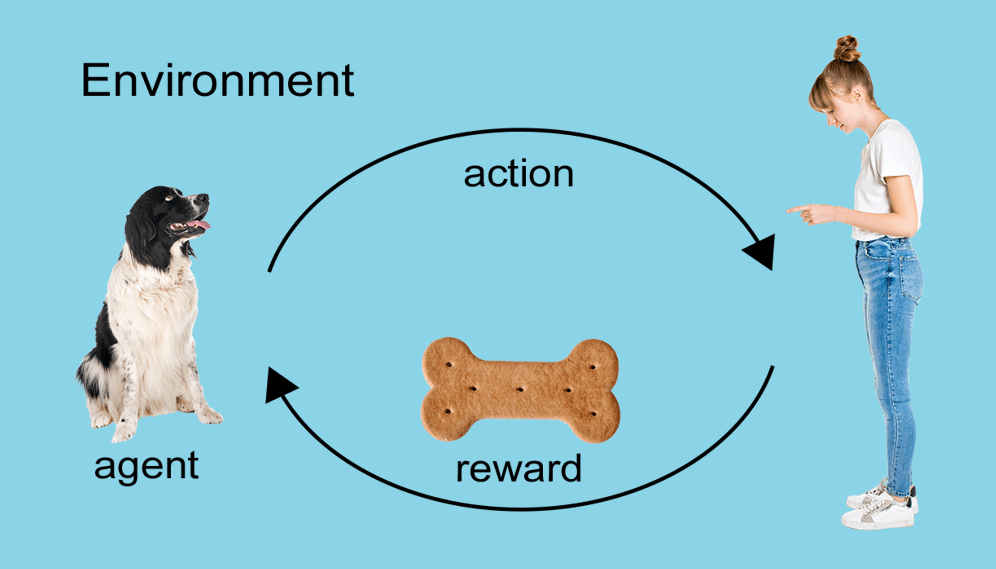
Reinforcement learning differs from previous methods in that it does not need training data, but simply works and learns via the described reward system.
It is a learning method which predicts a sequence of decisions that promise the highest possible success rate.
| Real Business Case |
| Google’s Deep Mind has evolved its AlphaGo software to create AlphaGo Zero. AlphaGo was a software designed to play the ancient Chinese strategy game Go, using data from hundreds of thousands of games as input. AlphaGo Zero, unlike previous versions of AlphaGo, uses the reinforcement learning approach. With the “Zero” standing for zero external data, the AI was given the rules of the game and then asked to figure out the best approaches to win. |
Ad recommendation systems are moving into reinforcement learning algorithms as they need to be customised and personalised continuously to achieve a higher click-through rate (CTR). With the reward (success rate) being users who click on the ad, the AI will adapt its decision-making every time to increase its chances of getting clicked. For example, the AI might infer that users who view the ad more than once in a period of 10 minutes are most likely to click on it, compared to users who view it only once.
Summary
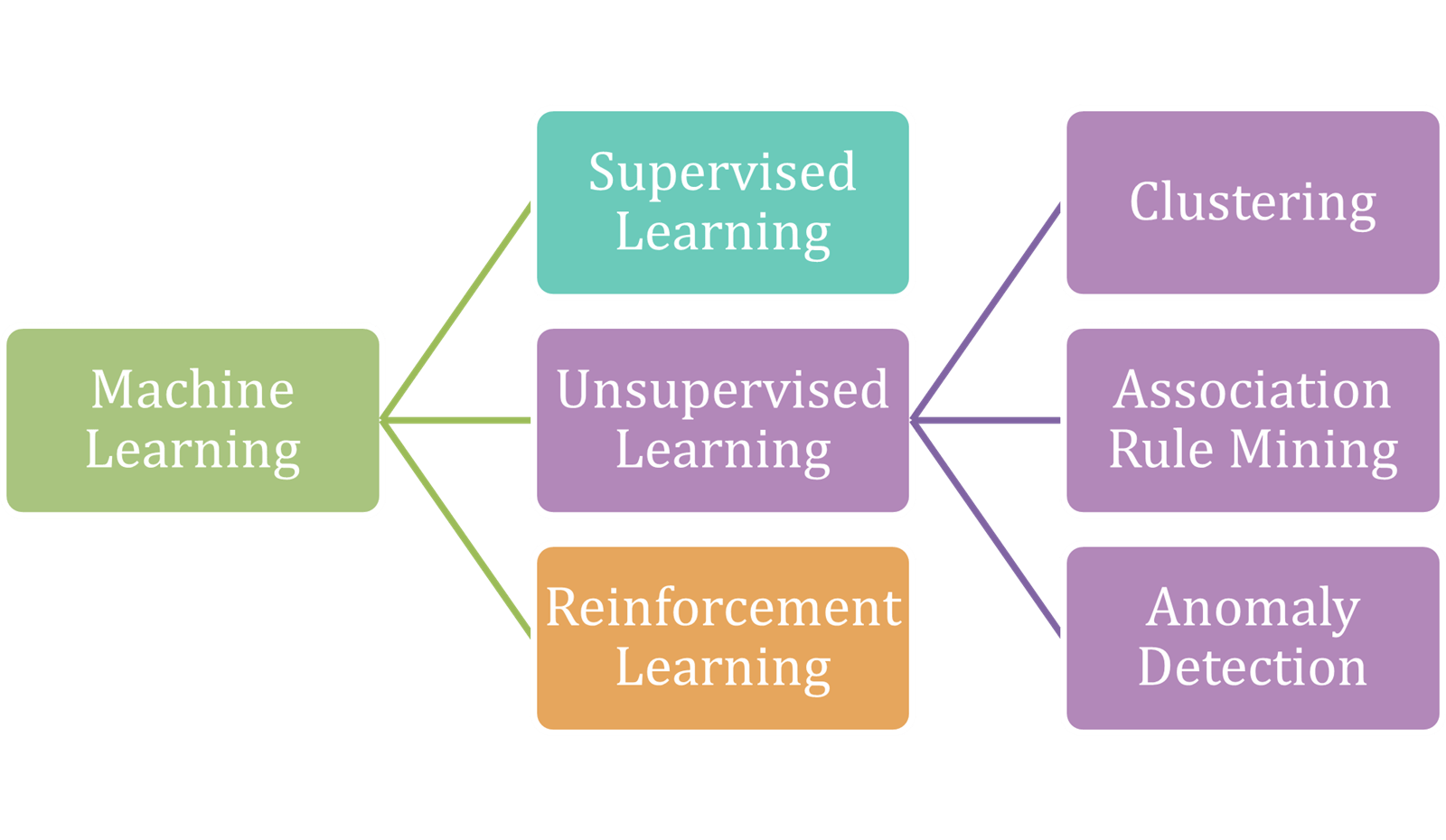
This article has attempted to explain Machine Learning as simply as possible and categorised its subsets as follows:
ML is a specific but very important part of AI that really starts to set computers on the path towards adaptation. ML-based AI solutions are designed, in theory, to continuously improve as they interact with ever-increasing volumes of data. An ML-based solution should not make the same mistake twice, but with this comes risk, where correlation and causation are conflated into one. While Autonomous (driverless) cars, customer support chatbots, Alexa and Netflix suggestions are some examples of AI that have already changed our lives – mostly for the better – there are many areas where there remains reason to be sceptical. But the pace of change is unlikely to slow; AI will eventually transform all the industries created by humans and will create a plethora of new ones.
